Pythonは、自然言語処理、つまりテキストデータを分析することもできます。
その初歩として、形態素解析というものをやる方法をまとめてみました。

Pythonでは、数字ではなく文字を分析できる
分析というと、数字での分析が思い浮かびます。
だからこそ、数値化や数字で表現することが求められることが多いのです。
とはいえ、数値化できるものには限りがあり、文章や文字からの分析は、ヒトがやっています。
しかし、AI(AIっぽいものを含む)だと、その分析が、できるのです。
AI時代のプログラミング言語といわれるPythonでも、文字の分析ができます。
たとえば、これまで読んだ本のタイトルのリストを準備し、

それをPythonで解析すると、たとえば、『会計と決算書がパズルを解くようにわかる本』だと、このようにまず細かく文章をわけます。
(こういうのを、形態素解析といいます)

分けたうえで、集計したり、判断したりするのです。
「分析」という言葉自体、分けるという意味がありますので、その最初のステップと言えるでしょう。
「決算書」が、「決算」と「書」にわかれてしまっていますが、これは自分で辞書をつくることにより現状でも解消はできます。
さらには、その単語ごとに分析し、集計してみました。
仕事 568
術 542
人 472
新書 454
ため 328
ビジネス 282
会社 277
という上位の結果です。
私がメディアメーカーというサイトで登録している、4829冊のタイトルを分析しました。
私のページはこちらです。
仕事のために読んでいる本が多いので、やはり、「仕事」が1位でした。2位の「術」とあわせて「仕事術」も多いかと。
9月9日(今日)開催するインプット入門セミナーの題材としても使っています。
こういったデータを、売上と結び付けてもおもしろいでしょうね。
以上のような集計を、プログラミング=Pythonを使えば、ささっと、数秒でできるわけです。
データが増えれば、多少は時間もかかるようになりますが、ヒトのようにミスの可能性は増えません。
データを集めるしくみをつくり、プログラミングし、実行するだけです。
Pythonでのjanomeを使った形態素解析
Pythonでテキスト分析(テキストマイニングともいいます)、形態素解析をする方法をまとめてみました。
Pythonの初期設定については、こちらを参考にしていただければ。
PythonとEXCELマクロ比較。Pythonの導入・設定【Windows・Mac両対応】 | EX-IT
PythonでExcelからデータ読込→サイトで交通費検索→Excelへデータ書込 | EX-IT
janomeで形態素解析
Pythonは、ライブラリといういわえる外部のアプリのようなものを使えます。
今回もjanomeというライブラリを使いました。
コマンドプロンプトやターミナルでインストールするなら、
pip install janome
上記の記事にあるPycharmでやるなら、[ファイル]→[設定]でインストールするか、
from janome.tokenizer import Tokenizer
と、本文を書けば、インストールすることもできます。
形態素解析のプログラムはこういったもので、たったこれだけです。
from janome.tokenizer import Tokenizer # テキストファイル読込 エラーの場合 ,encoding='utf-8' v_data = open(r'C:\Users\info0\Dropbox\0 INBOX\book7.txt').read() # 形態素解析し、出力 for v_token in Tokenizer().tokenize(v_data): print(v_token)
from janome.tokenizer import Tokenizer
↓
Janomeを読み込みます。
# テキストファイル読込 エラーの場合 ,encoding='utf-8' v_data = open(r'C:\Users\info0\Dropbox\0 INBOX\book7.txt').read()
↓
#で始まる行はコメントなので、自由です。
Vで始まる単語は、変数で任意のものです(最近はこう書くのがしっくりきています)
open(〇〇).read()で、テキストファイルを読み込みます。
ファイル名は、cからはじまるものを書きましょう。
’で囲み、最初にrをつけるのがポイントです(rはrowの意味で、これがないと、\を\にしなければいけなくなります)
〇=△という式なので、v_dataに開いたテキストファイルを入れるという意味です。
テキストファイルは、メモ帳で保存するならファイル形式を「utf-8」にし、txtの後に ,encoding=’utf-8’をつけます。
※そうしないとこのエラーがでます。
UnicodeDecodeError: ‘cp932’ codec can’t decode byte 0xef in position 0: illegal multibyte sequence
いったんExcelに貼り付けて、テキスト(タブ区切り)で保存したほうが楽です。
この場合、,encoding=’utf-8’は入りません。

# 形態素解析し、出力 for v_token in Tokenizer().tokenize(v_data): print(v_token)
↓
ここでは、v_tokenという変数を使って、Tokenizer().tokenize(○○)という処理をしています。
〇〇にはテキストファイルが入るので、さきほどのv_dataを入れるわけです。
次にprintで出力すると、v_token、つまり処理結果が出力されます。
forは繰り返しですので、繰り返しデータの数だけ処理してくれるわけです。
出てきた結果は、品詞やその活用形、読み方などのリスト。
こうやってかんたんに分析できるのは、janomeのおかげです。

Janome Anaryzer・Tokenfilterで形態素解析したものをフィルタリングし集計
Janomeには、Anaryzerという機能もあります。
これがあれば、フィルタリングや集計もできるのです。
v_data = open(r'C:\Users\info0\Dropbox\0 INBOX\book7.txt').read()
from janome.analyzer import Analyzer
from janome.tokenfilter import *
# 名詞でフィルタリングし、カウントする設定
v_filter = Analyzer(token_filters=[POSKeepFilter(['名詞']), TokenCountFilter(att='base_form')])
# 形態素解析し、カウントし、降順にソートして出力
for v_word, v_count in sorted(v_filter.analyze(v_data), key=lambda x: -x[1]):
print(v_word, v_count)
v_data = open(r'C:\Users\info0\Dropbox\0 INBOX\book7.txt').read()
↓
上記と同じようにテキストファイルを読み込み、v_dataとします。
from janome.analyzer import Analyzer from janome.tokenfilter import *
↓
janomeのAnalyzerとTokenFilterを読み込みます。
# 名詞でフィルタリングし、カウントする設定 v_filter = Analyzer(token_filters=[POSKeepFilter(['名詞']), TokenCountFilter(att='base_form')])
↓
token_filters=[POSKeepFilter([‘名詞’])は、名詞でフィルタリング、
TokenCountFilter(att=’base_form’)]は、基本形でカウント
という意味です。
これらのオプションを付けて、Analyzerで処理しています。
# 形態素解析し、カウントし、降順にソートして出力 for v_word, v_count in sorted(v_filter.analyze(v_data), key=lambda x: -x[1]): print(v_word, v_count)
↓
処理した結果が出力されるのは、
単語 数
という形式です。
それぞれにv_word、v_countと名前を付けて、
v_filter.analyze(v_data)
でフィルタリングをかけたv_dataの分析結果を繰り返し出力しています。
sorted(〇〇, key=lambda x: -x[1]):
でついでに多い順にソートしています。
lambda(ラムダ)は、ラムダ関数というもので、そういうもんだと思っておいたほうがいいでしょう。
その後の関数のx: -x[1]で、1列目(0、1と数えるのでカウントした数)を多い順(-Xの-)でソートしています。
Pythonで分析してみたもの。経理データ、ブログ記事、アンケート、プロフィール
その他同様に、分析してました。
経理データ
私の経理データです。
独立から11年の経理、家計簿データが入っていて、36591。

「振込」が多いのは、「振込手数料」ではなく、「振り込まれた」ものです。
この辺の精度は改善余地があります。
会議、打ち合わせ、Kindle、Amazonあたりがやはり多いです。
スタバも…。
ブログ記事
ブログ記事すべてを分析していたのですが、それなりに時間がかかるので、過去5年間のアクセスが多い記事のタイトルを分析してみました。
Excel、仕事、方法、時間などが入っているとよく読まれているというデータです。

ブログ記事の分析が終わったので、追記します。
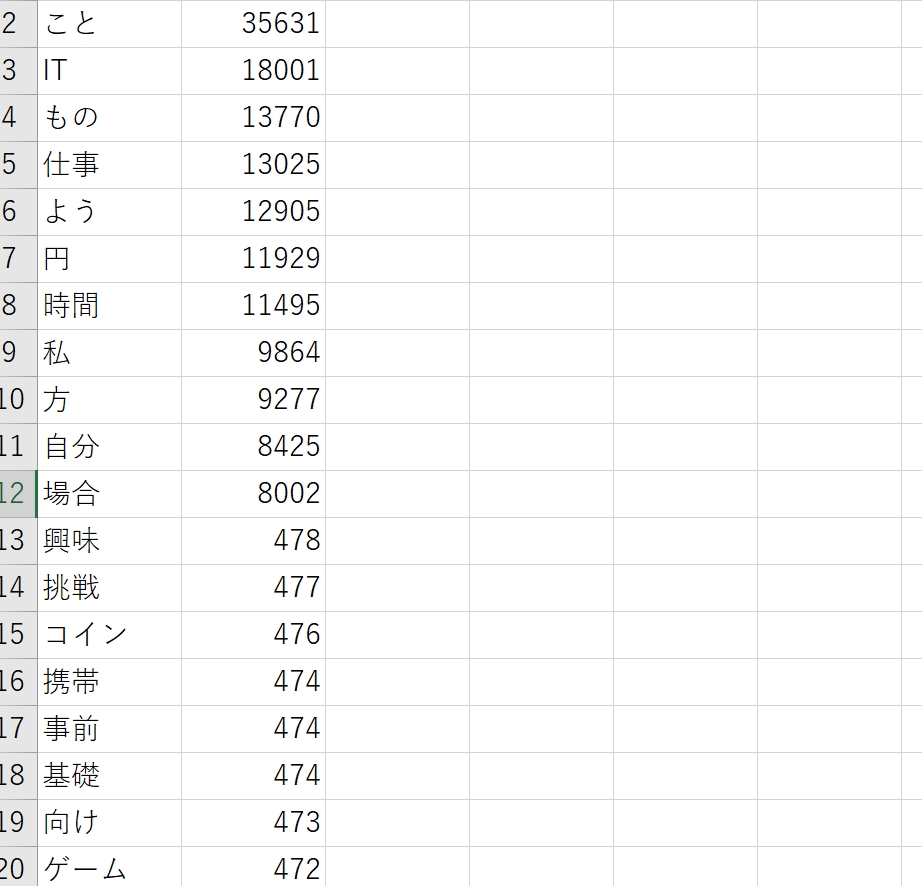
4797記事の本文を分析し、上位はこうなっていました。
「IT」がやはり多く、「仕事」も多いです。
「円」、「時間」も多く、「興味」「挑戦」が多いのも意外でした。
「事前」や「基礎」が多いのは私のポリシーと一致します。
「ゲーム」が意外と多いです……。
アンケート
セミナー後のアンケートは、フォームから入力していただき、データ化しています。
これも分析してみました。
「セミナーを知っていただいた理由」は、このとおり。
ブログやメルマガがメインです。

「なぜこのセミナーを選んだいただいたか」。
ここでは、私(井ノ上)だったから、他になかったからというのがうれしい答えなのです。
他と選んでどうこうもうれしいのですが、他にないようなものをやっているつもりですので。
「井ノ上」や「ブログ」が上位にあるのはうれしいことです。
「他」も60カウントありました。

プロフィール
私のブログのプロフィールも分析してみました。
ラン、スイム、バイクが上位・・・。
トライアスロンのレース歴を載せているからです。
税理士がようやく37個。
分析対象としてはあんまりですね。

テキストデータをいろいろ分析してみるとおもしろいです。
ぜひ、Pythonで書いてみていただければ。
アプリを使うより、自分で書いて動かしてみるのも大事です。
昨日は、午後から娘と2人だったので、動物園、ディズニーランド、アンパンマンミュージアムなどいろいろ候補がある中、アンパンマンミュージアムへ。
自宅近くから横浜までバスで行ってみました。
バスのほうが楽です。娘がおとなしくしてれば。
横浜駅からはいつも歩いています、10分ほど。
横浜のオービィ(屋内の動物園)も気になるのですが、評価があまりよくなく大混雑なのでやめました。
■昨日の1日1新
※詳細は→「1日1新」
アンパンマンミュージアム カーニバル
アンパンマンミュージアム うどん
横浜までバスで
アンパンマンミュージアム 風船
■昨日の娘日記
アンパンマンミュージアム、周辺のストアやレストランも充実していて、昨日はミュージアム(2人で3000円)に入らず楽しみました。
アンパンマンのブロック、風船をゲットし、うどんやパンも。
そして、念願のアンパンマンマント(好きでよくマントをつけてます)もゲットしました。
入場料以上にお金かかりましたが。
■著書
『税理士のためのプログラミング -ChatGPTで知識ゼロから始める本-』
『すべてをがんばりすぎなくてもいい!顧問先の満足度を高める税理士業務の見極め方』
ひとり税理士のギモンに答える128問128答
【インボイス対応版】ひとり社長の経理の基本
「繁忙期」でもやりたいことを諦めない! 税理士のための業務効率化マニュアル
ひとり税理士の自宅仕事術
リモート経理完全マニュアル――小さな会社にお金を残す87のノウハウ
ひとり税理士のセーフティネットとリスクマネジメント
税理士のためのRPA入門~一歩踏み出せば変えられる!業務効率化の方法~
やってはいけないExcel――「やってはいけない」がわかると「Excelの正解」がわかる
AI時代のひとり税理士
新版 そのまま使える 経理&会計のためのExcel入門
フリーランスとひとり社長のための 経理をエクセルでトコトン楽にする本
新版 ひとり社長の経理の基本
『ひとり税理士の仕事術』
『フリーランスのための一生仕事に困らない本』
【監修】十人十色の「ひとり税理士」という生き方